

Title: ADDITIONS: Simulated sky catalogs for Wide Field Galaxy Surveys
Authors: Risa H Wechsler, Joseph DeRose, Michael T Busha, et al.
Institution of first author: Department of Physics, Stanford University, Stanford, CA; Kavli Institute for Particle Astrophysics & Cosmology, Stanford, CA; SLAC National Accelerator Laboratory, Menlo Park, CA
Status: Published in ApJ [open access]
In recent years, the fields of cosmology and extragalactic astronomy have seen an explosion of scientific discovery, fueled by advances in numerical simulations of cosmology and galaxy formation, coupled with the dissemination of ever-increasing amounts of observational data. According to our current understanding of the evolution of the Universe, galaxy formation and cosmology are closely linked, with galaxies serving as tracers of the large-scale distribution of matter in the Universe because they are fundamentally connected to their dark matter (DM) halo. In other words, to study the underlying distribution of dark matter in the Universe and to examine the fundamental physics underlying the cosmology we observe today, we must rely on statistically significant samples of galaxy observations.
Ideally, to interpret such observations, one can imagine numerically simulating the entire history of the Universe, with all the underlying physics — as is done in cosmological hydrodynamic simulations — and comparing the resulting galaxy populations to observed samples. However, this is a computationally intensive task and therefore not easily scalable to large volumes (such as the size of our universe). Instead, we often use faster approaches to create synthetic catalogs of galaxies based on our understanding of the physical connection between galaxies and DM halos, such as Halo occupation distributions (which describe how many galaxies we expect to find in a given DM halo and where we expect them), semianalytical models (where physical processes are “painted” onto a numerical simulation of gravitational structure formation) and Adjustment of subhalo frequency (where galaxies are matched to their host shalos by matching the number density of galaxies above a given mass to the number density of DM haloes above a given mass). Crucially, all of these approaches require a relatively high-resolution simulation of DM structure formation from which to build the galaxy population. Inspired by the usefulness of pseudo-catalogues, but the concomitant lack of computationally efficient tools to create them, today’s authors present ADDGALS (Adding Density-Determined Galaxies to Lightcone Simulations), which offers a relatively computationally inexpensive approach to constructing realistic, synthetic catalogs of galaxies to create modest -resolution simulations of the DM structure.
Broadly speaking, the ADDGALS algorithm can be summarized in the steps given in Figure 1. That said, the authors leverage a machine learning-inspired approach to use data from a high-resolution simulation to fit their models for the connection between galaxies and their DM halos and survey data to fit a model that correlates galaxy properties with the local DM density distribution, so both sets of models can then be applied to a lower resolution simulation to create a spurious catalog of galaxies. Simply put, this algorithm helps a dark matter simulation to figure out where the galaxies should be placed and what they should look like when observed in a survey.
Therefore, the first part of the algorithm is to figure out where the galaxies need to go (steps 0-2 in Figure 1). The authors divide this process into two steps. First, they assign the largest, the so-called “central” galaxies to their halos by establishing a statistical relationship between the halo mass and the brightness of the central galaxy, the p(Mright|MVir) in steps 1 and 2 of Figure 1. Then they need to populate the halos with satellite galaxies by establishing a relationship between the large-scale DM density and the galaxy size, the p(R|Mrightz) shown in Figure 1. This distribution, for which they take a form based on their simulations, gives the probability that we would see an M-sized galaxyright, at a redshift of z in a region of DM density R (technically this is the size of the region, so it’s labeled R, but it’s associated with a fixed mass, so we can think of it as a density). The authors then calibrate these two relationships based on a high-resolution simulation. With these two calibrated probability distributions — the central brightness-halo-mass and density-magnitude relationships — they can take a lower-resolution simulation and statistically assign galaxies to the simulated DM halos, yielding a catalog of galaxies with positions, velocities, and orders of magnitude.
The next step is to associate spectral energy distributions (SEDs) — the curves that describe an object’s emitted energy versus wavelength — with the galaxies placed in the simulation (steps 3-4 in Figure 1). This is done in a similar statistical way as assigning galaxies to halos, except this time the authors use a sample of 600,000 real galaxies from the Sloan Digital Sky Survey (SDSS) as their “training set” of SEDs. To find out which SED belongs to which synthetic galaxy, the authors note that they can use the distance to the nearest massive DM halo as a good predictor of the observed gr color. Given a fixed galaxy size, this means they can use abundance matching to assign colors to galaxies depending on the local DM environment. They then select the SEDs associated with the galaxy’s assigned color value and use these to calculate an observed brightness in each band for those galaxies. In order to realistically compare these synthetic catalogs with data observed in a real survey (which, for example, will have a limited size that it can observe), the authors also introduce synthetic errors, such as noise from the galaxy’s flow and the Heaven.
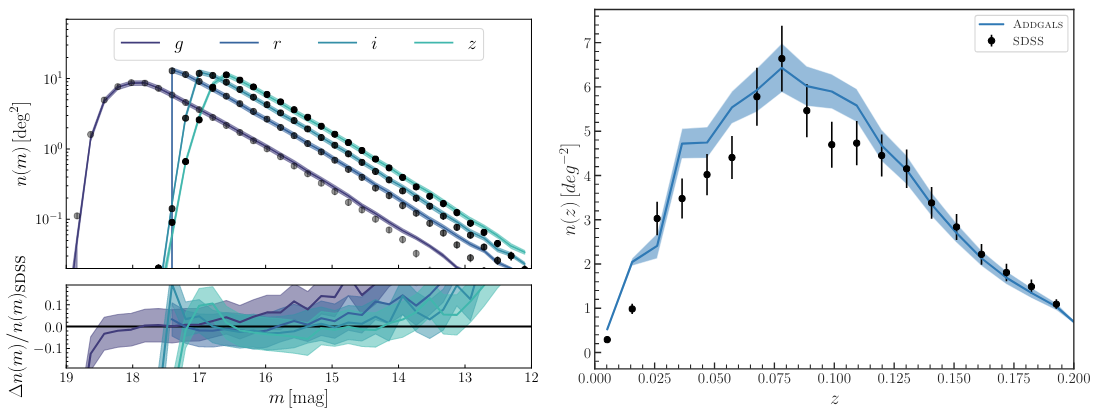
Finally, the authors demonstrate the validity of this approach by comparing the galaxy distribution generated by ADDGALS with actual SDSS data as presented in Figure 2, showing good agreement between the observed number and color of galaxies at different redshifts and sizes. The algorithm described in today’s paper provides a computationally inexpensive way to generate mock survey data and has already been applied to a variety of surveys and contexts, allowing scientists to easily test methods that can be applied to upcoming surveys and cosmological probes, for example rate that have done so applied to existing surveys.
While the work in this paper is not quite as easy as ABC or Do-Re-Mi, today’s authors have done their best to make the creation of the synthetic galaxy catalog as easy as (following steps) 1, 2, 3 (and 4 in Illustration 1)!
Astrobite edited by Graham Doskoch
Credit for featured image: adapted from YouTube
About Sahil Hegde
I’m a freshman astrophysics graduate student at UCLA. I am currently using semi-analytical models to study the formation of the first stars and galaxies in the universe. I received my BA from Columbia University and am originally from the San Francisco Bay Area. Outside of astronomy, I play tennis, surf (read: wipe out), and play board games/TTRPGs!
#Adding #Galaxies #easy #onetwothree
Leave a Comment